 Can Vision-Language Models Solve the Shell Game?
Can Vision-Language Models Solve the Shell Game?
Abstract
Visual entity tracking is an innate cognitive ability in humans, yet it remains a critical bottleneck for Vision-Language Models (VLMs). This deficit is often obscured in existing video benchmarks by visual shortcuts. We introduce VET-Bench, a synthetic diagnostic testbed featuring visually identical objects that necessitate tracking exclusively through spatiotemporal continuity. Our experiments reveal that current state-of-the-art VLMs perform at or near chance level on VET-Bench, exposing a fundamental limitation: an over-reliance on static frame-level features and a failure to maintain entity representations over time. We provide a theoretical analysis drawing connections to the state-tracking problem, proving that fixed-depth transformer-based VLMs are fundamentally limited in tracking indistinguishable objects without intermediate supervision due to expressivity constraints. To address this, we propose Spatiotemporal Grounded Chain-of-Thought (SGCoT): generating object trajectories as explicit intermediate states. Leveraging Molmo2's object tracking ability, we elicit SGCoT reasoning by finetuning on synthesized text-only data for alignment. Our method achieves state-of-the-art accuracy above 90% on VET-Bench, demonstrating that VLMs can reliably solve the video shell-game task end-to-end without external tools.
VET-Bench

VET-Bench is a synthetic diagnostic benchmark designed to isolate spatiotemporal perception from frame-level appearance cues. Videos are rendered using three.js, supporting full synthetic variation in color, material, texture, lighting, and camera viewpoint. VET-Bench ensures that no single frame reveals either (i) the target's identity or (ii) the swap operation, forcing VLMs to rely exclusively on fine-grained spatiotemporal perception across frames.
Results
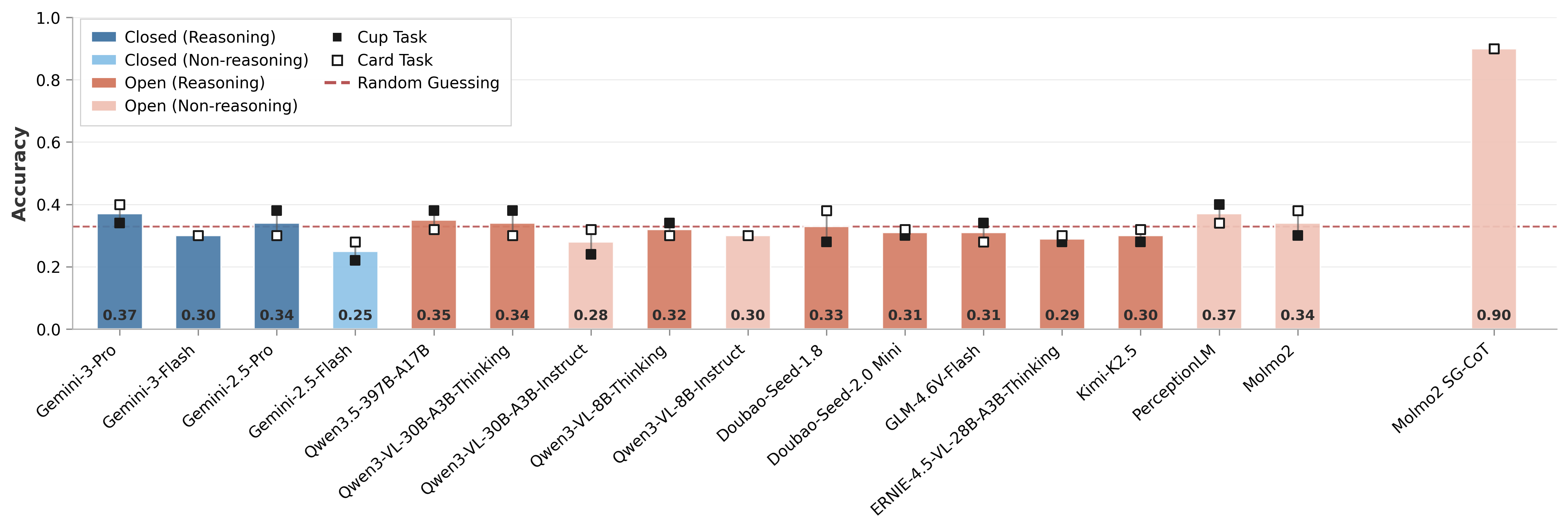
Performance of 16 state-of-the-art VLMs on VET-Bench, consisting of 50 cups-game and 50 cards-game videos featuring 3 objects and 5 swaps (~12 seconds). All existing VLMs perform near the random guessing baseline (33%). Our fine-tuned Molmo2-SGCoT achieves over 90% accuracy.
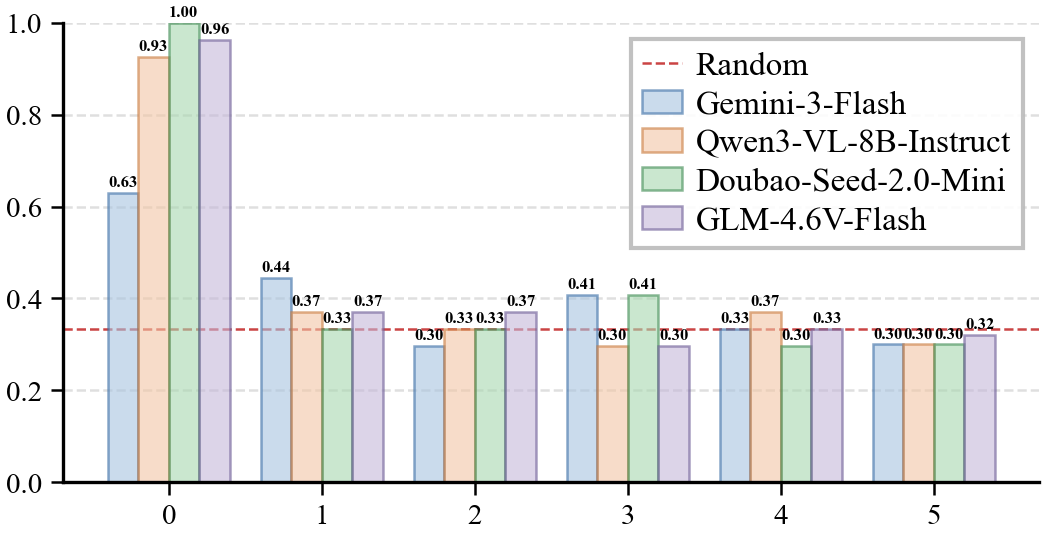
(a) Accuracy vs. Swap Count
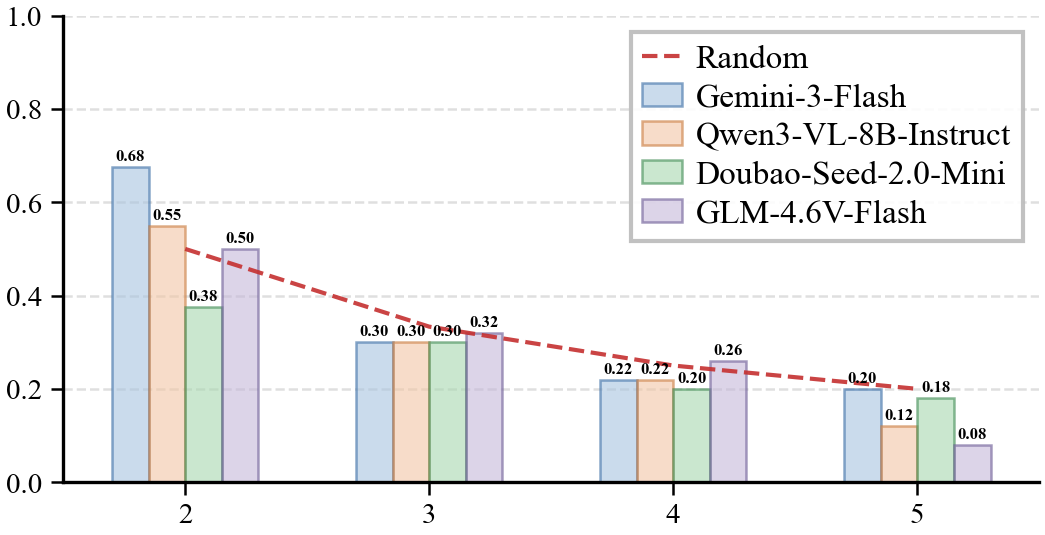
(b) Accuracy vs. Object Count
Swap count: For non-shuffled episodes, most models achieve near-perfect accuracy. Performance drops substantially with just one swap and quickly converges to random guessing.
Object count: Even at N=2 (the simplest case), models fail to significantly outperform the random baseline. Accuracy scales as 1/N, indicating that models resort to random guessing rather than genuine entity tracking.
Comparison with Existing Benchmarks
Visual Shortcuts in the Perception Test
The Perception Test includes shell-game-style clips, but many contain appearance cues that bypass the need for tracking. These include distinctive cups that allow re-identification by appearance, and transparent cups that directly reveal the target.


Example frames from videos involving distinct cups in the Perception Test.


Example frames from videos involving transparent cups in the Perception Test.


Visual shortcuts: unedited cut frames at the end reveal the answer by showing the cups being lifted.
Comparison with VideoReasonBench
VideoReasonBench includes cups-game-like tasks, but the swap operations are explicitly indicated by arrows overlaid on the frames. These visual annotations effectively serve as symbolic "swap tokens", allowing models to reason about state transitions from static in-frame cues. In contrast, VET-Bench has no such frame-level cues—correctly solving the task requires exploiting spatiotemporal continuity across frames.

VideoReasonBench

VET-Bench
VideoReasonBench provides explicit frame-level cues (red arrows) highlighting swap operations, which are absent in VET-Bench.
Spatiotemporal Grounded Chain-of-Thought (SGCoT)
We propose SGCoT, which leverages Molmo2's native object tracking capability to generate spatiotemporal grounded object trajectories as intermediate states before providing the final answer.
<tracks coords=\"0.0 1 500 504;0.5 1 500 504;1.0 1 500 504;1.5 1 500 431;2.0 1 571 306;2.5 1 664 293;3.0 1 735 389;3.5 1 750 504;4.0 1 750 504;4.5 1 750 504;5.0 1 750 504;5.5 1 750 504;6.0 1 750 504;6.5 1 750 504;7.0 1 750 504;7.5 1 750 480;8.0 1 704 330;8.5 1 614 280;9.0 1 532 352;9.5 1 500 493;10.0 1 539 339;10.5 1 630 280;11.0 1 710 341;11.5 1 750 504;12.0 1 750 504">the Queen of Hearts</tracks>Answer: right.
BibTeX
@misc{liu2026visionlanguagemodelssolveshell,
title={Can Vision-Language Models Solve the Shell Game?},
author={Tiedong Liu and Wee Sun Lee},
year={2026},
eprint={2603.08436},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.08436},
}